
AlphaFold was selected by Science and Nature as one of the Top 10 scientific breakthroughs in 2021. Unfortunately, its overall training time remains exorbitantly high, at 11 days. To this end, HPC-AI Tech and Helixon have jointly released open-source FastFold, an accelerated implementation of AlphaFold. By introducing novel GPU optimizations and large model training techniques, FastFold can successfully reduce AlphaFold training and inference time. Astoundingly, our results indicate that FastFold can reduce AlphaFold’s training time from 11days to 67 hours as well as greatly accelerate inference time by up to ~11.6 times.
Check out the project over here: https://github.com/hpcaitech/FastFold
Protein Structure Prediction and AlphaFold
Proteins are the material basis of life and support almost all functions of life. They are large, complex molecules made up of chains of amino acids, and the role of proteins depends largely on their unique three-dimensional structure. There are currently over 200 million known proteins, yet we only know a fraction of their precise structures. Figuring out the shape that a protein folds into based on its underlying composition of amino acids is known as the “protein folding problem” and has troubled the scientific community for the last 50 years.
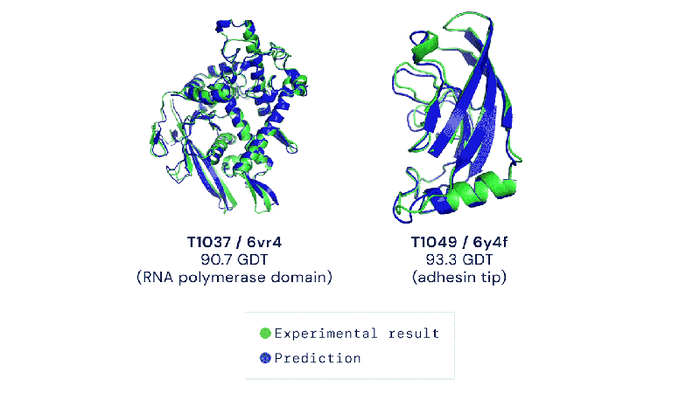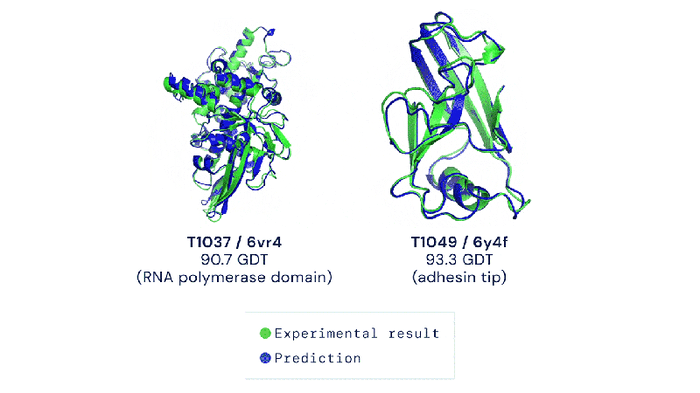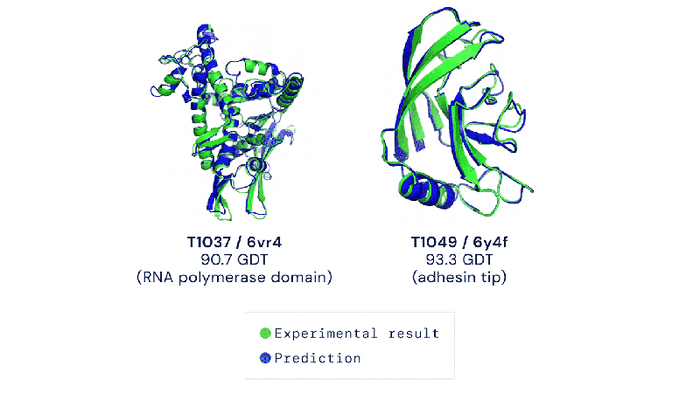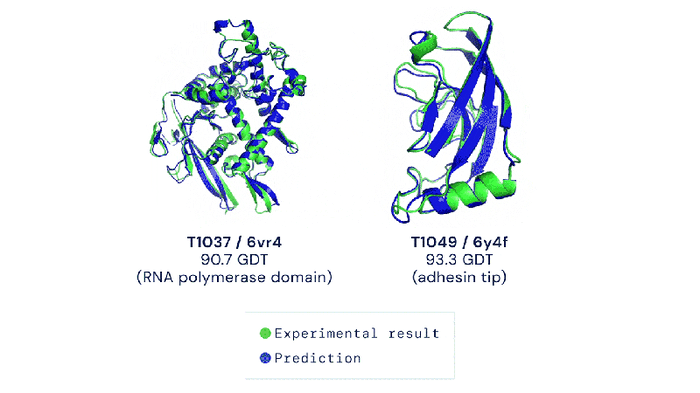
Methods that attempt to tackle the “protein folding problem” fall into two buckets: experimental and computational. Experimental methods can obtain accurate protein structures, but require a fair bit of money. Scientists are thus increasingly focusing their attention on computational methods, which can perform high-throughput protein structure prediction at low costs. In 2020, Google DeepMind introduced the latest generation of AlphaFold, which successfully introduced the Transformer model to aid scientists in the “protein folding problem”. It is an end-to-end model architecture that obtains accurate prediction results.
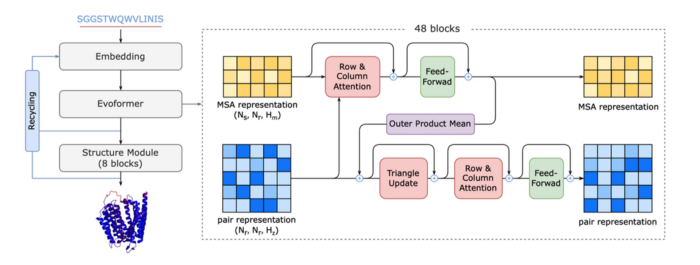
Unfortunately, the Transformer-based AlphaFold model also poses a number of computational challenges.
- The limited global batch size inhibits the scalability of training to more nodes using the data parallel approach as it leads to a drop in accuracy. As a result, it takes around 11 days to train AlphaFold with its official open-source implementation on 128 Google TPUv3s.
- AlphaFold consumes an enormous amount of memory, more so than what conventional modern GPUs can handle. During inference, the longer the sequence, the greater the demand for GPU memory.
- During inference, long sequences require extensive GPU memory. Furthermore, the inference time of long sequences can last up to several hours when using the naive AlphaFold model.
FastFold
To solve the challenges mentioned above and get the most performance out of AlphaFold, we proposed an accelerated implementation: FastFold, a highly efficient implementation of protein structure prediction for both training and inference. To the best of our knowledge, FastFold is the first in its domain of being a performance optimized model for both the training and inference of protein structure prediction models. FastFold successfully introduces large model training techniques and reduces the time and economic cost of AlphaFold during both the training and inference stages significantly.
FastFold consists of a high-performance implementation of Evoformer, the backbone structure of AlphaFold, and an innovative model parallelism strategy called Dynamic Axial Parallelism. Coupled with another technique: pairwise asynchronous arithmetic, FastFold achieves high model parallelization scaling efficiency, surpassing current mainstream model parallelism techniques.
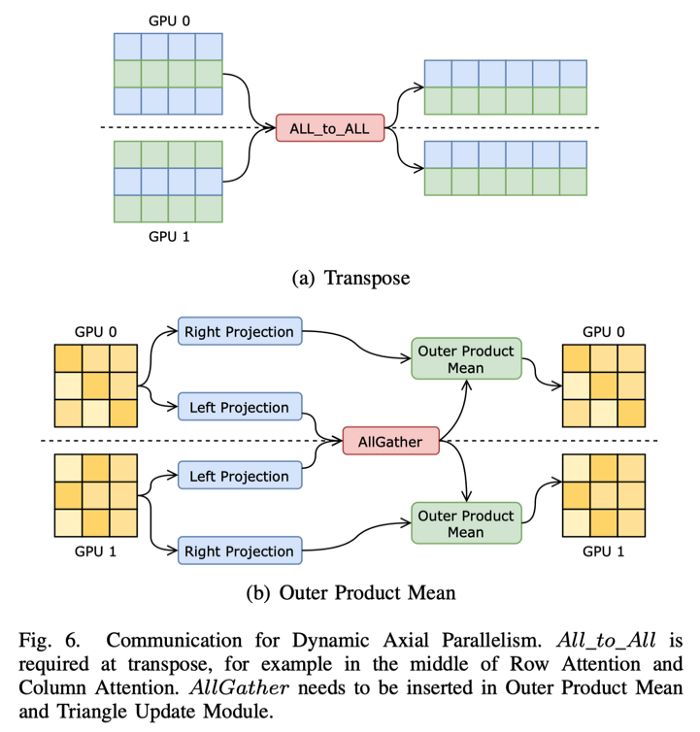
Dynamic Axial Parallelism. FastFold is the first attempt to introduce model parallelism into the AlphaFold model. We innovatively propose Dynamic Axial Parallelism (DAP) according to the computational characteristics of AlphaFold. Unlike traditional Tensor Parallelism (TP), DAP chooses to divide the data in the sequence direction of AlphaFold’s features and uses the communication collective: All_to_All. DAP has several advantages over tensor parallelism:
- It supports all modules in Evoformer;
- It has a smaller communication overhead;
- It incurs lower memory consumption;
- It facilitates additional communication optimizations to be used in conjunction with model training, such as overlapping communication with computation.
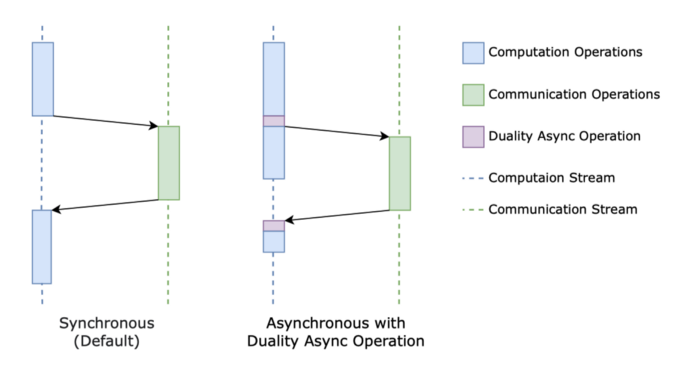
Duality Async Operation. The Duality Async Operation consists of a pair of communication operators. During the forward propagation of the model, the former operator triggers asynchronous communication, then some computation without dependencies is performed on the Computation Stream, and then the latter operator blocks the asynchronous communication until the communication is completed, and then the subsequent computation is performed. When the model is propagated backward, the latter operator will trigger the asynchronous communication and the former operator will block the communication. Using Duality Async Operation allows us to easily overlap computation with communication during the forward and backward propagation steps on a dynamic graph framework like PyTorch.
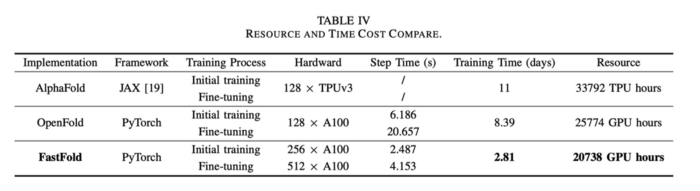
Performance
FastFold has significant performance improvement overall current implementations of AlphaFold.
1) Training. FastFold can reduce the training time to 2.81 days. Compared to AlphaFold, which takes 11 days to train, we can experience a 3.91 fold increase in training. Compared to OpenFold (a replica of AlphaFold from Cambridge University), FastFold can gain up to a 2.98 fold increase in training whilst reducing the economic cost by 20%. We scaled FastFold to a supercomputer with 512 A100 GPUs, and the aggregated peak performance reached 6.02 PetaFLOPs with a scaling efficiency of 90.1%.
2) Inference. FastFold has significant performance advantages across all short, long and extremely long sequences.
(1) In the case of short sequence inference, up to 1K, FastFold improves single-GPU inference performance by 2.01 ∼ 4.05 times and 1.25 ∼ 2.11 times compared with AlphaFold and OpenFold, respectively.
(2) For long sequence inference, of lengths 1K to 3K, FastFold can significantly reduce the inference time using distributed inference, improving 7.5 ∼ 9.5 times compared to OpenFold and 9.3 ∼ 11.6 times compared to AlphaFold.
(3) Both OpenFold and AlphaFold are unable to reason about extremely long sequences longer than 3K because of Out of Memory (OOM), nonetheless FastFold can use the computational and memory resources of multiple GPUs to accomplish the task of extremely long sequence inference due to its distributed inference support.
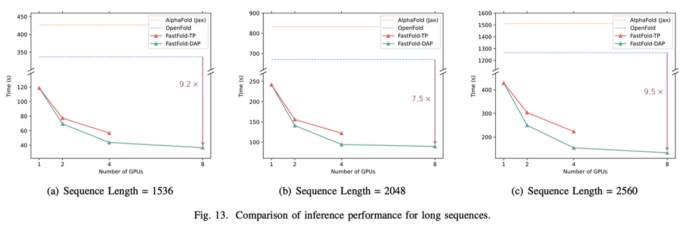
FastFold, our accelerated implementation of AlphaFold, significantly reduces the time it takes to train as well as the economic cost of the AlphaFold model. It will greatly facilitate the revolutionary innovation and development of next-generation drug discovery, protein design, antibody design and other application scenarios.
The Hero Behind
The success of the FastFold project is strongly supported by the open source AI infrastructure Colossal-AI. The massively parallel AI system: Colossal-AI , through efficient multidimensional parallelism, large-scale optimization libraries, adaptive task scheduling, and the elimination of redundant memory, aims to create an efficient distributed AI system as the kernel of a deep learning framework; to help users conveniently maximize the efficiency of AI deployment while minimizing deployment costs.
Check out Colossal-AI over here:
https://github.com/hpcaitech/ColossalAI
Join Us
HPC-AI Tech is a global team and the core members are from the University of California, Berkeley, Stanford University, Tsinghua University, Peking University, National University of Singapore, Singapore Nanyang Technological University, and other top universities in the world. Currently, HPC-AI Tech is recruiting full-time/intern AI system/architecture/compiler/network/CUDA/SaaS/k8s core system developers, open source program operators, and sales personnel.
HPC-AI Tech provides highly competitive compensation packages. Our staff can also work remotely. You are also welcome to recommend outstanding talents to HPC-AI Tech. If they successfully join HPC-AI Tech, we will provide you with a recommendation fee of thousands of US dollars.
Resume delivery mailbox: hr@hpcaitech.com
Portal
FastFold Paper Link: https://arxiv.org/abs/2203.00854
FastFold Project Link: https://github.com/hpcaitech/FastFold
Colossal-AI Project Link:https://github.com/hpcaitech/ColossalAI
Funding
HPC-AI Tech raised 4.7 million USD from top VC firms in just 3 months after the company was founded. For more information, please email contact@hpcaitech.com
Comments