
ColossalAI-MoE
Increasing the amount of data and the model size is widely recognized as the most direct method to enhance the performance of neural networks. For example, GPT-3 increased its parameters to billions with future models expected to follow. While larger models improve performance, they also require immense computational power. Alternatively, the Mixture of Experts (MoE) strategy selectively activates parameters which efficiently increases the model's parameter count. MoE's recent potential is attracting growing attention.
We are delighted to announce a comprehensive upgrade to the ColossalAI-MoE module, which is specifically designed to enhance MoE models. This upgrade aims to assist users in training and deploying expert models efficiently and stably. From training to inference, we provide a thorough solution to inject innovation into your projects! Here are our key features:
-
OpenMoE Support: Comprehensive training and inference systems for OpenMoE, the first open-source MoE transformer that only includes the decoder. This facilitates a smoother mastery of MoE applications within the open-source community.
-
Heterogeneous Parallelism: Our innovative EZ-MoE technology addresses the unique characteristics of MoE training for more efficient heterogeneous parallelism. This makes the user's work more convenient and productive.
-
Low-Level Optimization: We support both the efficient application of MoE but also a series of low-level optimization methods to ensure that the MoE model achieves outstanding performance.
Open-source repository:
Mixture of Experts (MoE)
For approaches in the mainstream deep neural network, all model parameters typically engage in processing input data simultaneously. This results in increasingly expensive computational resource requirements as the number of pre-trained model parameters grows. However, MoE technology transforms this scenario. MoE allows users to selectively activate a portion of the model parameters to handle different input data, meaning that as the number of parameters increases, the demand for computational resources remains relatively stable. This approach manages computational resources, and alleviates the computational burden of large-scale models. Specifically, in the case of Transformer models, the implementation of MoE is illustrated in the following diagram.
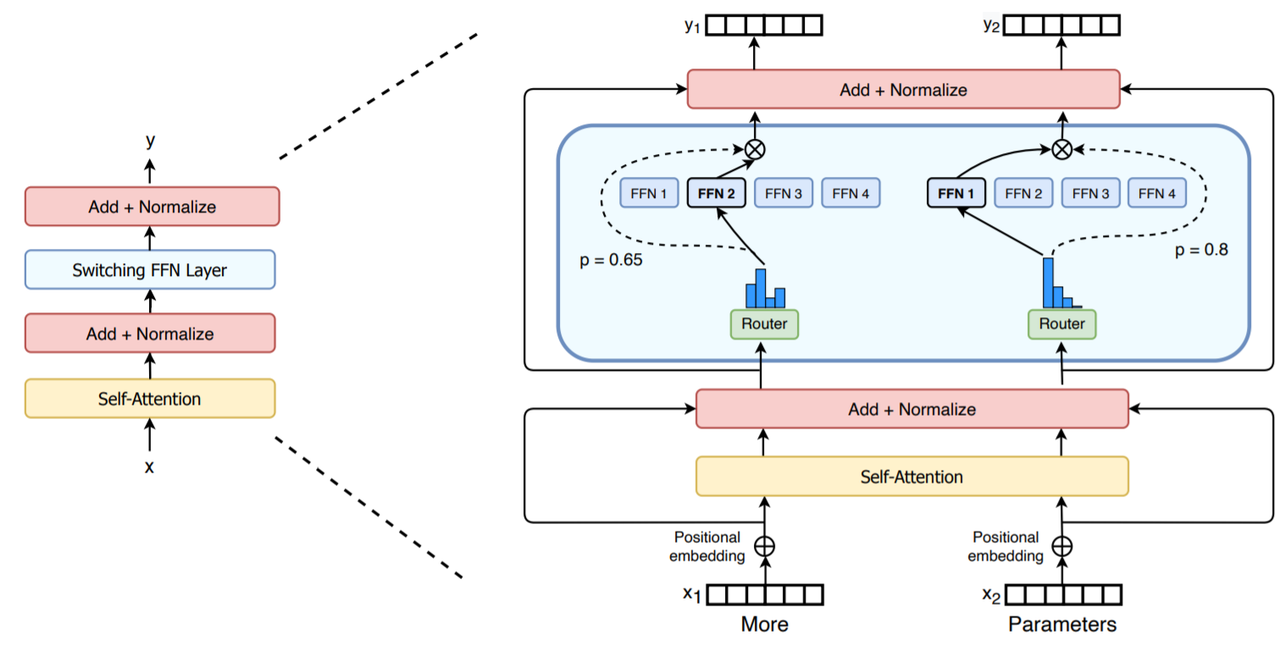
In each layer, the structure of the attention component remains unchanged. However, in the multi-layer perceptron (MLP) section, there are multiple sets of specialized feedforward neural networks. These networks are activated to process input data through a gating network known as the "Router." This enables the model to allocate computational resources appropriately, thereby enhancing efficiency.
OpenMoE
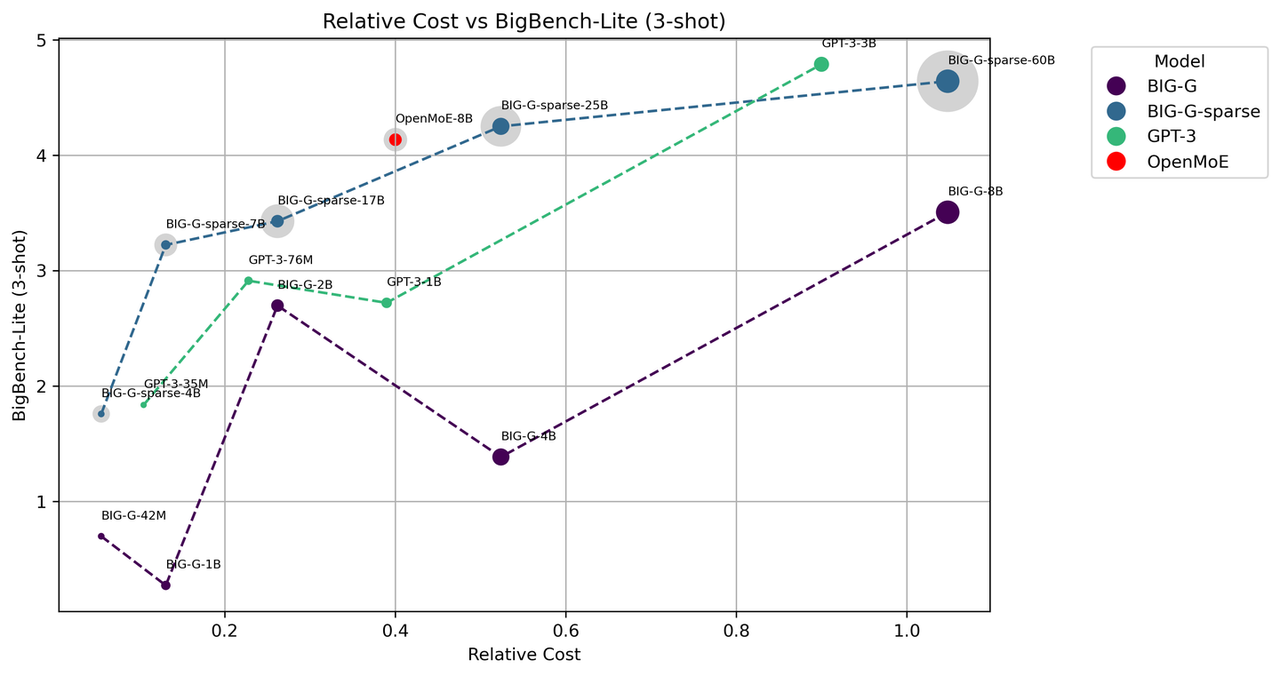
OpenMoE is the first open-source MoE Transformer model that exclusively includes the decoder component. Its enhancements are built upon ST-MoE and have been refined through training on The RedPajama and The Stack Dedup datasets. Performance testing of OpenMoE was conducted on BigBench-Lite and used a Few-Shot learning approach. The model's performance was compared to BIG-G, BIG-G-Sparse (a MoE model developed by Google), and GPT-3 by assessing model performances under relative cost considerations. Relative cost is calculated as the ratio between the number of activated parameters and the number of trained tokens. The size of each data point represents the number of activated parameters while the light gray data points indicate the total parameter count of the MoE model. The graph depicts that under equivalent cost conditions, OpenMoE demonstrates a better performance.
OpenMoE is implemented using Jax, and ColossalAI-MoE is the first time efficient PyTorch open-source support has been provided for this model. This advancement broadens the user base that can engage with and utilize the model. In ColossalAI-MoE, we have incorporated state-of-the-art hybrid parallelism techniques and low-level optimizations, resulting in significantly superior training performance compared to PyTorch FSDP and DeepSpeed-MoE. Taking OpenMoE-8B as an example, our training performance is up to 9 times faster than PyTorch and 42% faster than DeepSpeed, as illustrated in the figure below:
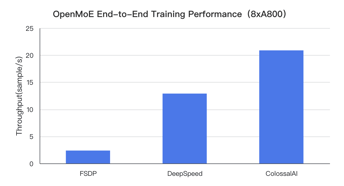
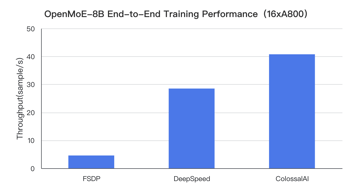
Limitations of Expert Parallelism
In typical training scenarios for Mixture of Experts (MoE), methods known as Expert Parallelism are often used. The idea behind Expert Parallelism is that different experts can be allocated to various computing devices, thus reducing memory consumption and improving training efficiency. In this process, each device sends its data to the corresponding device where the expert is located, based on the routing rules of the MoE model. Subsequently, the device awaits the completion of computations by the expert before producing the results. Throughout the process, communication is required between every expert pair, a process referred to as AlltoAll communication.
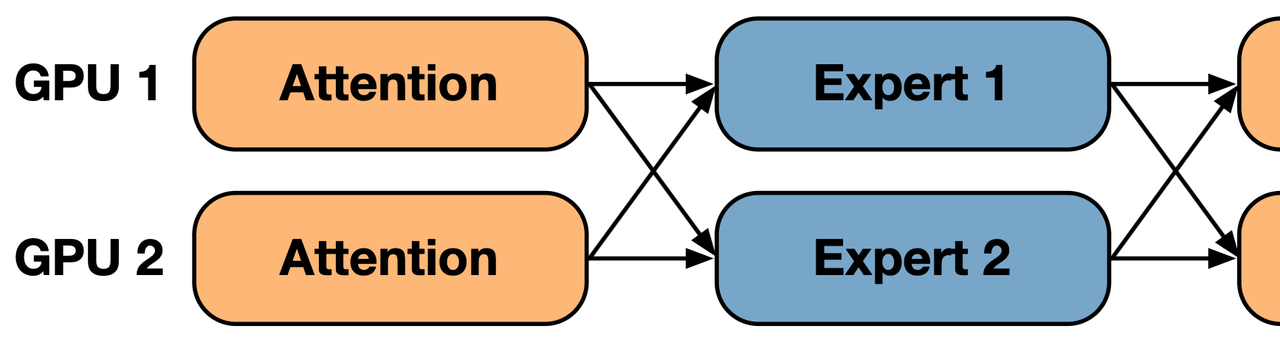
However, a major drawback introduced by expert parallelism is the extended time required for AlltoAll communication and an imbalanced computational workload. The fundamental reasons for these two issues stem from the large scale of expert parallelism, and present two main challenges:
-
Exponential Growth in AlltoAll Communication: The scale and frequency of AlltoAll communication grows exponentially, leading to increased communication time and consequently reducing overall training efficiency.
-
Imbalance in Computational Workload: Despite efforts to achieve load balancing, the number of experts allocated to each computing device remains low. This results in an imbalance in the workload within individual batches, leading to significant performance fluctuations in the training process.
When attempting to reduce the scale of expert parallelism or when the number of machines exceeds the number of experts, additional parallel dimensions like data parallelism need to be introduced. This involves replicating experts or using model parallelism to distribute an expert across multiple computing devices. However, these approaches bring forth new challenges. For instance, when using data parallelism, the MoE model's parameters become excessively large, resulting in significant time consumption for parameter communication. On the other hand, model parallelism decreases computational efficiency and adds extra communication time. These challenges must be addressed when dealing with large-scale MoE models.
Heterogeneous Expert Parallelism
To address these issues, we propose Heterogeneous Expert Parallelism, also known as EZ-MoE (Hierarchical EP-ZeRO MoE). In EZ-MoE, heterogeneous ZeRO parallelism is integrated with expert parallelism, aiming to reduce the parallel scale of EP without sacrificing performance.
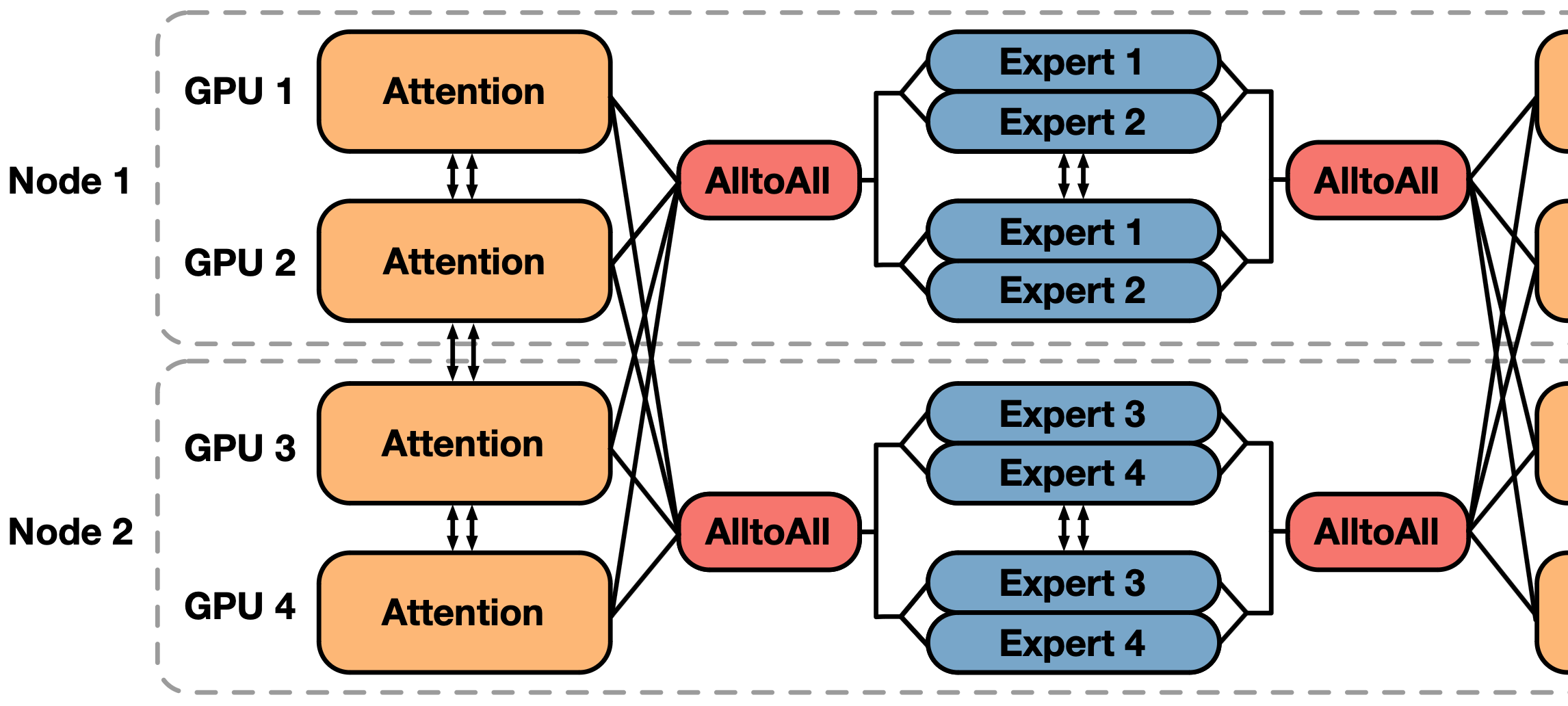
Traditional data parallel methods require synchronizing parameters across different devices which results in significant communication overhead. Our proposed novel parallel structure takes a different approach. For the MoE module, we create multiple copies within the same device, limiting parameter communication of the device and restricting cross-device communication to AlltoAll communication. The underlying design philosophy is as follows:
-
Although the number of parameters in the MoE module increases substantially, the tensor size is unchanged, resulting in AlltoAll communication data volume being much smaller than the data volume for parameter communication, usually occupying only 3%-10%.
-
Despite the lower efficiency of AlltoAll communication, its shorter transmission time compensates for this due to its limited impact from inter-machine communication bandwidth constraints.
-
The scale of expert parallelism is reduced.
-
Computation can offset the time overhead for AlltoAll communication.
Considering these factors, AlltoAll communication is a more optimized choice. However, this approach also leads to a substantial increase in memory consumption for each expert on the card. To address this issue, we employ a heterogeneous ZeRO parallelism strategy. For non-MoE modules, we use global ZeRO parallelism since these modules have relatively fewer parameters. In OpenMoE, non-MoE module parameters typically account for around 20% of the total parameter count, making it feasible to handle this data through asynchronous communication. For MoE modules, communication volume is not significant due to fast intra-machine interconnect speeds and the low presence of experts on each device. Additionally, we introduce pipeline parallelism that effectively reduces communication time during large-scale training.
Load Balancing
Existing load balancing algorithms often neglect the layout and communication overhead of current MoE models. Using our parallel approach, we developed a load balancing algorithm designed specifically for the existing arrangement of experts. The goal is to achieve load balancing based on the current distribution of experts with minimal communication costs.
We have designed a lightweight algorithm based on a beam search approach. Initially, we use a beam search strategy for expert exchanges in the machine, considering different combinations of expert exchanges one by one. The score of each exchange combination is evaluated based on the resulting load balance and corresponding communication overhead, and the k combinations with the highest scores are chosen. We continue expert exchanges until load balancing is achieved. Compared to traditional dynamic programming methods, this approach is more efficient and adaptable to existing expert arrangements, and provides more analytical possibilities.
We employ this method to search for the best exchange possibilities within the machine. If satisfactory results cannot be obtained within the machine, we extend the search to inter-machine interactions, minimizing inter-machine communication costs.
Low-level Optimization
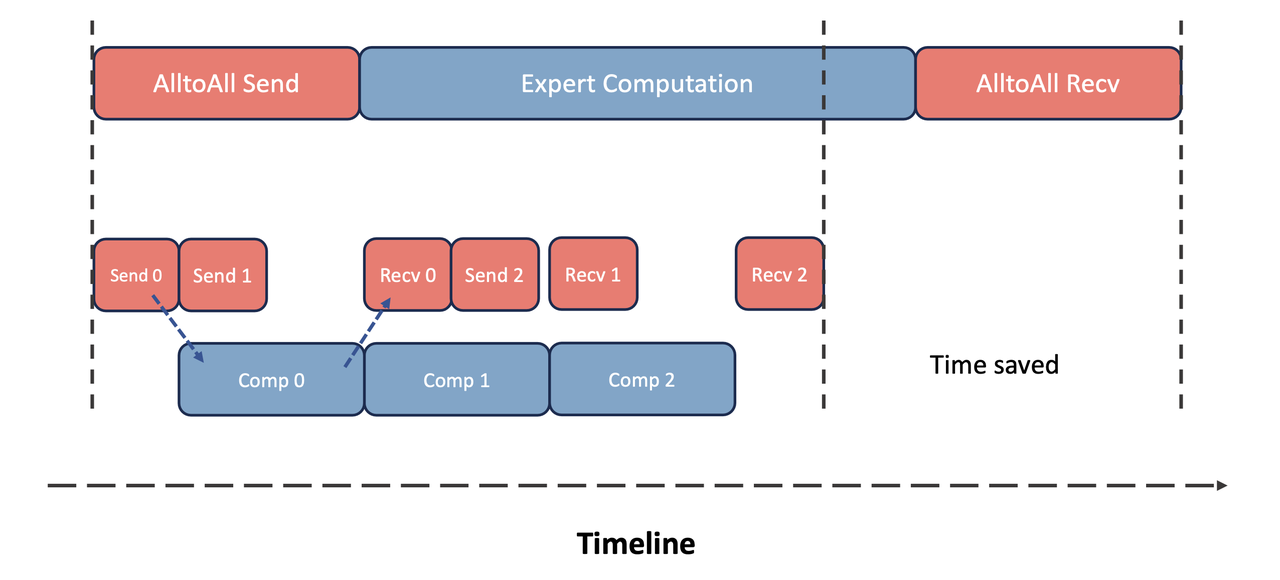
In MoE, the AlltoAll communication module is typically considered the most time-consuming part. To address this issue, we implemented a pipeline parallelism approach that overlaps the AlltoAll communication and computation processes within MoE, significantly reducing the required communication time. This technique is especially effective in reducing large communication time during multi-machine training. Additionally, the AlltoAll operator in NCCL is not specifically optimized, relying solely on multiple parallel Send/Recv operations. This makes it challenging to adapt to different communication environments within and between nodes. To overcome this, we have developed a hierarchical AlltoAll operator, and leverage the advantages of a hybrid network. This operator first utilizes the bandwidth advantage of NVLink for message aggregation and rearrangement within a node. Once message aggregation is complete, inter-node communication is initiated, increasing the volume of single communication instances. Subsequently, the operator rearranges the data and sends it to different GPUs, preserving the original semantics of the operator.
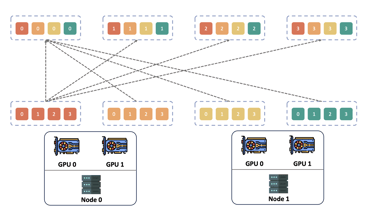
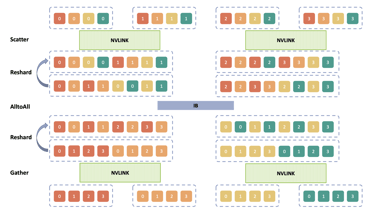
NCCL AlltoAll Hierachical AlltoAll
Simultaneously, for OpenMoE's more time-consuming modules, such as the MoE router, large-scale embedding layers, and FFN (FeedForward Network), a series of efficient optimization strategies, including kernel fusion and computational process optimizations has been added. Additionally, we have custom-tailored operators, contributing to an improvement in computational efficiency of over 30%. The introduction of Flash Attention technology has been incorporated to further enhance computational efficiency. This series of low-level optimization strategies positions ColossalAI-MoE as outstanding in both communication and computation, significantly boosting overall performance.
Open-source repository:
https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/openmoe
Reference
Fedus, William, Barret Zoph, and Noam Shazeer. "Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity." The Journal of Machine Learning Research 23.1 (2022): 5232-5270.
Fuzhao Xue, Zian Zheng, Yao Fu. "OpenMoE: Open Mixture-of-Experts Language Models." https://github.com/XueFuzhao/OpenMoE.
Nie, Xiaonan, et al. "HetuMoE: An efficient trillion-scale mixture-of-expert distributed training system." arXiv preprint arXiv:2203.14685 (2022).
Zhai, Mingshu, et al. "{SmartMoE}: Efficiently Training {Sparsely-Activated} Models through Combining Offline and Online Parallelization." 2023 USENIX Annual Technical Conference (USENIX ATC 23). 2023.
Rajbhandari, Samyam, et al. "Deepspeed-moe: Advancing mixture-of-experts inference and training to power next-generation ai scale." International Conference on Machine Learning. PMLR, 2022.
Comments