Deep recommendation models (DLRMs) have become critical for deep learning applications in IT companies. DLRMs can be used to improve user experience for video recommendations, shopping searches, and companies’ advertisements. However, DLRMs have several limitations, including difficulties managing too much user data, frequent model updates, and high training costs.
DLRMs first search an embedding bag (EmbeddingBags), and then go through a dense DNN. Embedded tables usually hold more than 99% of the memory in the DLRM, and only 1% of the computation requirements. With the help of GPU’s on-chip high-speed memory (High Bandwidth Memory), and increased computing power, GPU has become the mainstream hardware for DLRM training. However, with the increasing research depth of recommendation systems, the embedding tables are also growing in size, and the limited GPU memory is not able to keep up. The question remains: How can we use GPU to efficiently train super-large DLRM models despite the limitation of GPU memory?
Colossal-AI has successfully used a heterogeneous training strategy to increase the number of NLP model training parameters capacity by hundreds of times at the same hardware. Recently, it has used a software cache method which dynamically stores the embedding table in the CPU and GPU memory to extend the parameters to the recommendation system. In relation to the software cache design, Colossal-AI also incorporates pipeline prefetching which reduces software cache retrieval and data movement overhead by observing future training data. At the same time, it trains the entire DLRM model on the GPU in a synchronized update manner, which can be scaled to multiple GPUs with the widely used hybrid parallel training method. Experiments show that Colossal-AI only needs to keep 1~5% of the embedding parameters in the GPU, and is still able to maintain excellent end-to-end training speed. Compared with other PyTorch solutions, the memory requirements are reduced by an immense magnitude, with a single GPU being able to train a terabyte-level recommendation model. As a result, the cost advantage is significant. For example, only 5GB of GPU memory can be used to train a DLRM that occupies a 91GB Embedding Bag. The training hardware cost is reduced from two NVIDIA A100s totaling about 30,000 USD, to an entry-level graphics card like RTX 3050 which only costs about 300 USD.
Open Source Repo:
https://github.com/hpcaitech/ColossalAI
Existing Techniques to Scale Embedding Tables
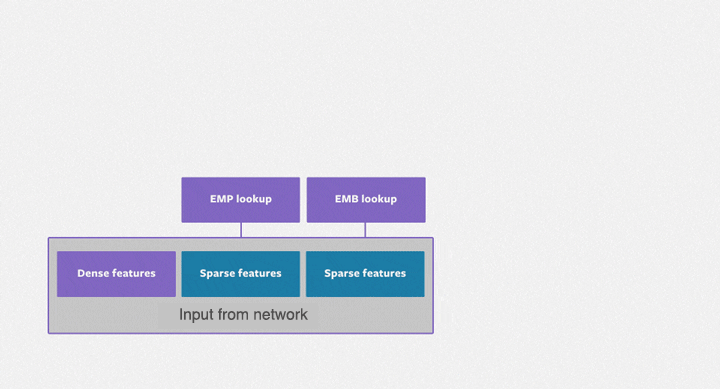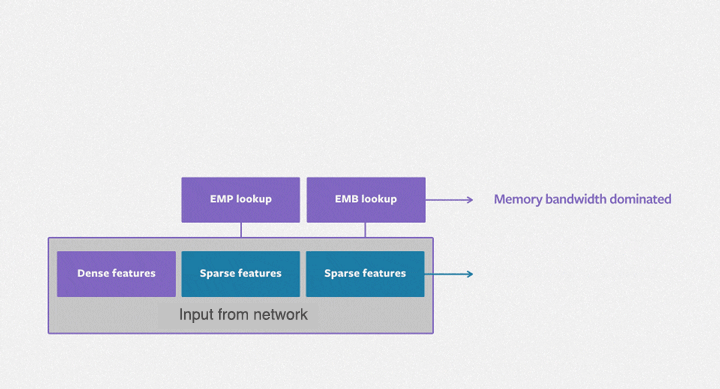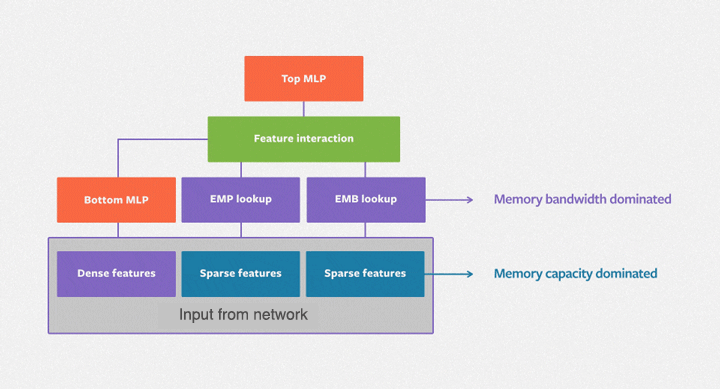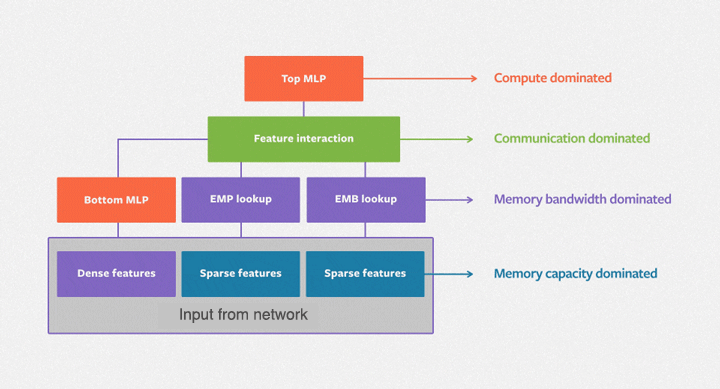
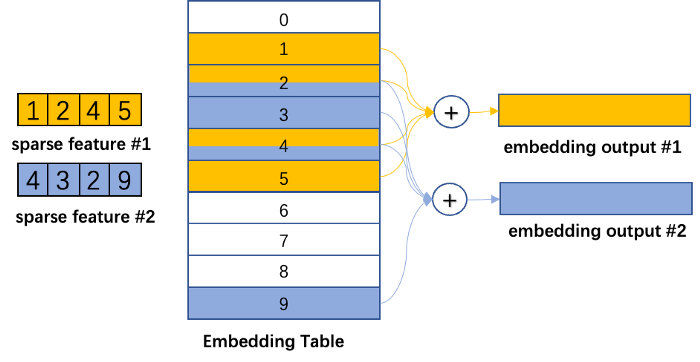
The purpose of the embedding table is to map categorical variables into floating-point variables. The following figure shows the training process of the embedding table in DLRMs. First, it identifies the corresponding records for each feature in the embedding table, outputs a feature vector through reduction operations (i.e. max, mean, and sum operations) and then inputs them to the subsequent dense neural network. The embedding table DLRM training process is comprised mainly of irregular memory access operations, so it is severely limited by the hardware memory access bandwidth.
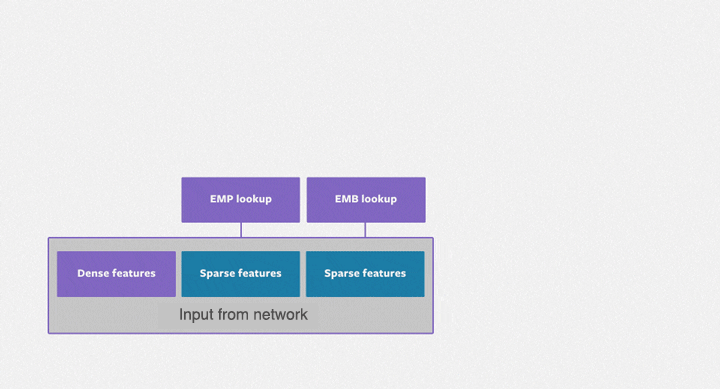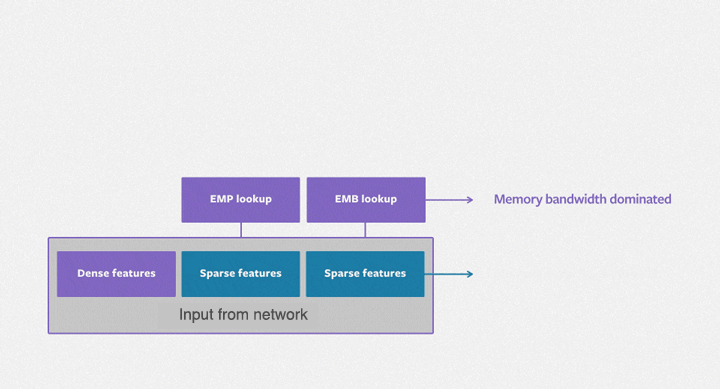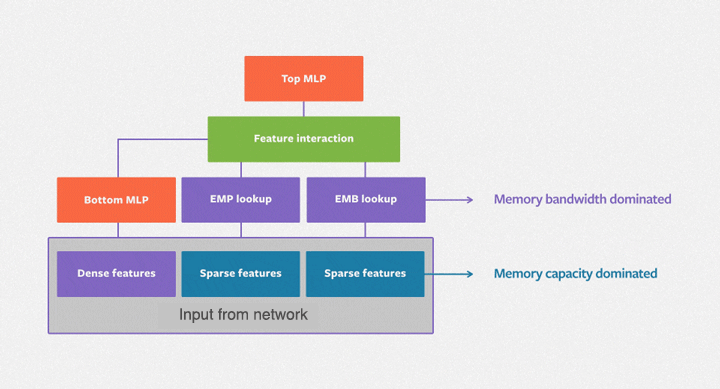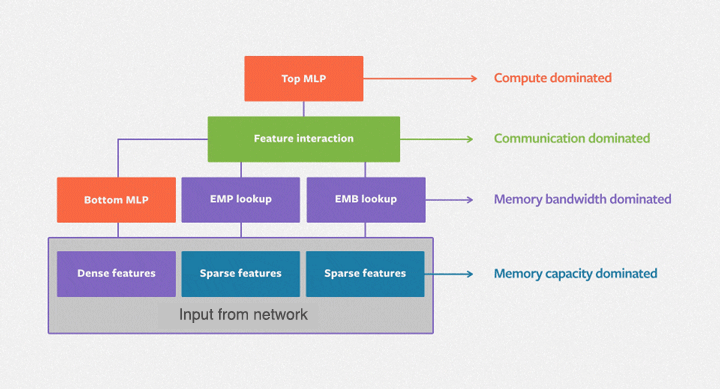
In real applications, the embedding table of a DLRM may reach hundreds of GB, or even TB levels, far exceeding the single GPU capacity of only a few tens of GB. There are many ways to increase the size of DLRM’s embedded table. Taking the memory hierarchy diagram of the GPU cluster shown in the figure below as an example, we can analyze the advantages and disadvantages of several common solutions.
GPU model parallelism: During this method, the embedding table is sharded and distributed in the memory of multiple GPUs, and the intermediate results are synchronized via the interconnection network between GPUs. The disadvantage of this method is that the workload of the embedded table may not be equal, and it is difficult to scale. Furthermore, the initial investment of adding GPUs is high, and the computing power of GPU is not fully utilized. DLRM mainly utilizes the HBM bandwidth of GPUs, while computing units are not utilized well.
Hybrid Training: This method starts by splitting the embedding table into two parts, one trained on the GPU and the other trained on the CPU. By using long-tail input data distribution, we can minimize the CPU computing and maximize GPU computing. However, as the batch size increases, it becomes difficult to ensure that all the data in the mini-batch hits the CPU or GPU. Additionally, since the DDR bandwidth and HBM differ by magnitude, even if just 10% of the input data is trained on the CPU, the entire system will slow down by at least two times. The CPU and GPU also need to transmit intermediate results, which requires lots of overhead communication, further slowing down the training speed. Consequently, researchers have designed methods like asynchronous updates to combat these issues, but asynchronous methods can cause uncertainty in training accuracy, and are not ideal for algorithm engineers.
Software Cache: All training is performed on the GPU with this method, and the embedding tables are kept in the heterogeneous memory space composed of the CPU and GPU. Each time the software cache is used, the used part is exchanged into the GPU. In this way, storage resources are expanded inexpensively while meeting the increased demand for embedded tables. Compared to using the CPU to calculate, the entire training process is completed on the GPU, making full use of the HBM bandwidth advantage. On the contrary, cache query and data movement of this method will bring additional performance loss.
Currently, there are some excellent software cache solutions for embedding tables, but they are often implemented using customized EmbeddingBags Kernel, such as fbgemm, or with the help of third-party deep learning frameworks. With native PyTorch, Colossal-AI can implement a unique set of software Cache EmbeddingBags, further optimize the DLRM training process, and propose a prefetch pipeline to further reduce Cache overhead.
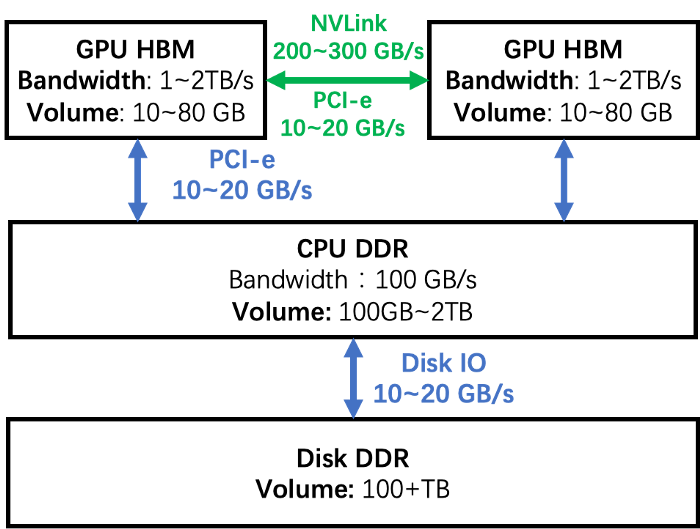
Memory Hierarchy of GPU clusters
Software Cache Design
Colossal-AI implements a class of CachedEmbedding which works as a subclass of the nn.Module in PyTorch and can replace the native PyTorch EmbeddingBag. It consists of software which manages the CPU and GPU memory. It maintains EmbeddingBag parameters as CPU Weight. A small part of the EmbeddingBag called the CUDA Cached Weight is stored as GPU memory, which will be used for future training. During DLRM training, records of the embedding table are first identified by the current mini-batch. If some records are not in the GPU yet, they are transmitted from the CPU Weight to the CUDA Cached Weight. If there is not enough space in the GPU, the LFU algorithm will be used to discard the least frequently used embedding records.
In order to query the cache efficiently, some auxiliary data structures are needed: the cached_idx_map is a 1-D array mapping the indices of records in the CPU Weight to the indices of CUDA Cached Weight, as well as the GPU access frequency. The ratio of the CUDA Cached Weight size to CPU Weight size is named cache_ratio and defaults to 1.0%.
The cache operates before each forward iteration to adjust the data in the CUDA Weight in three steps.
Step 1: Query CPU records: Query record indices of CPU Weight that need to be cached. This requires intersecting the cached_idx_map and the input of the current mini-batch.
Step 2: Query GPU records: Identify CUDA Cached weight that should be evicted according to frequency. This requires performing a top-k operation on the different sets of cache_idx_map and input of the current mini-batch.
Step 3: Data transmission: Free enough space on the CUDA Cached Weight for CPU Weight, which may lead to queried GPU records being transferred from GPU to CPU. Then move the to-be queried CPU records from the CPU Weight into CUDA Cached Weight.
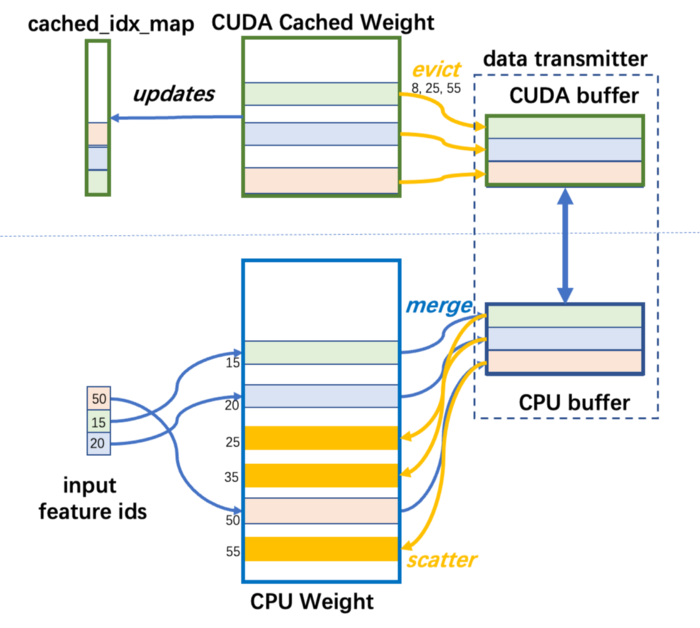
Cached EmbeddingBag Workflow
Improved Cache Design: Pipeline Prefetching
The processes in Step 1 and Step 2 of the Cache are memory demanding. In order to take advantage of the bandwidth on the GPU’s HBM, they are run on the GPU and implemented using drop-in API provided by PyTorch. The overhead of Cache operations is particularly prominent compared to the training operations of the embedding table on the GPU.
For example, for a training task that takes 199 seconds, the overhead of the cache operation is 99 seconds, which accounts for nearly 50% of the overall computing time. The main overhead of the Cache is mainly caused by Step 1 and Step 2 in the cache operation, and the base in the figure below shows the total time decomposition of the cache operation. The red and orange stages (Step 1, 2) account for 70% of the total cache overhead.
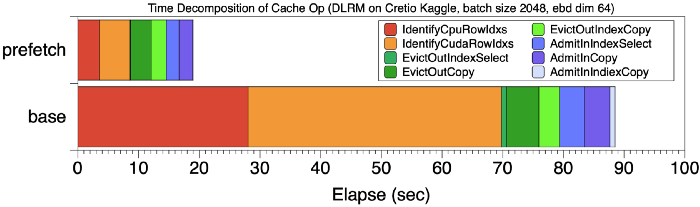
Time Decomposition of Cache Operation
The problem above arose because the traditional Cache strategy is somewhat “short-sighted”, so the Cache is adjusted according to the input of the current mini-batch, and most of the time is wasted on query operations.
In order to reduce the overhead time of the Cache, Colossal-AI has designed a “far-sighted” Cache mechanism. Instead of only performing Cache operations on the first mini-batch, Colossal-AI fetches several mini-batches that will be used later, and performs Cache query operations together.
As shown in the figure below, Colossal-AI uses prefetching to merge multiple mini-batches of data and conduct one cache operation after merging. It also uses a pipeline method to overlap the overhead of data loading and model training. As shown in the following figure, the number of mini-batches prefetched in the example is 2. Before starting training, it loads mini-batch 0 and 1’s data from disk to GPU memory, conducts Cache operation, and then performs forward and back propagation and a parameter update of these two mini-batches. This can simultaneously be read with the initial data of mini-batch 2 & 3, and this part of the overhead can overlap with the calculation.
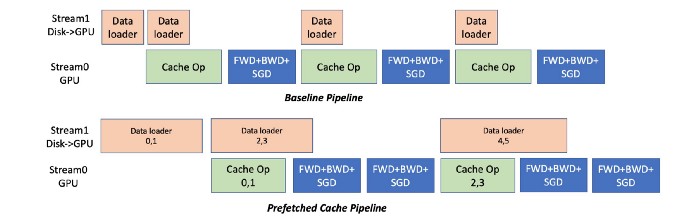
Pipeline Pre-fetched Cache
Compared with the execution mode of baseline cache, Figure [Time decomposition of Cache operation] compares the time decomposition of cache operation using 8 mini-batches prefetching with a baseline cache without prefetching. The total training time dropped from 201 seconds to 120 seconds, and the proportion of cache queries shown in the figure also dropped significantly.
To sum up, Cache pipeline prefetching brings two benefits.
1. Reducing Cache Query Overhead
The most obvious benefit of prefetching is reducing cache operation’s Step 1 and Step 2 overhead, so that this two-step operation accounts for less than 5% of the total training process. As shown in Fig. [Time Decomposition of Cache Operations], by pre-fetching 8 mini-batches of data, the overhead of cache queries is significantly reduced compared to the baseline.
2. Increasing CPU-GPU Data Movement Bandwidth
By concentrating more data and improving the granularity of data transmission, the CPU-GPU transmission bandwidth can be fully utilized. For the example above, the CUDA->CPU bandwidth is increased from 860MB/s to 1477MB/s, and the CPU->CUDA bandwidth is increased from 1257MB/s to 2415MB/s, almost double the performance gain.
Easy To Use
Our CachedEmbeddingBag is consistent with the basic usage of the PyTorch EmbeddingBag. When building a recommendation model, only a few lines of code can significantly increase the capacity of the embedding table and complete TB super-large recommendation model training at a low cost.
from colossalai.nn.parallel.layers.cache_embedding import CachedEmbeddingBag
# emb_module = torch.nn.EmbeddingBag(
emb_module = CachedEmbeddingBag(
num_embeddings=num_embeddings,
embedding_dim=embedding_dim,
mode="sum"
include_last_offset=True,
sparse=True,
warmup_ratio=0.7,
cache_ratio = 0.01,
)
Performance Benchmarking
The testbed is a GPU cluster with 8x NVIDIA A100 GPU (80GB) and AMD EPYC 7543 32-Core Processor (512GB) CPU. Colossal-AI also uses Meta’s DLRM model implementation, and evaluates on a Cretio 1TB dataset, as well as a synthetic dataset. The PyTorch training with the entire embedding table on the GPU is used as the baseline in the experiments.
Cretio 1TB
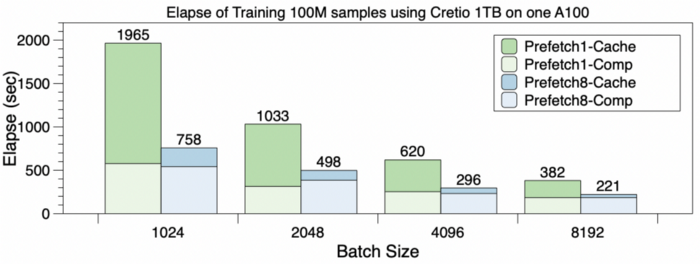
Cretio 1TB embedding table has 177,944,275 records, and its memory allocation takes up 91.10GB, with embedding dim equal to 128. To accommodate EmbeddingBags on one single GPU is impossible, even with top-end NVIDIA A100 with 80GB GPU memory.
Hopefully, Colossal-AI will make it possible to accomplish the training task on one GPU, with memory consumption dropping to 5.01 GB (lowering approx. 18 times), and show the possibility of training super large (terabyte-level) recommendation system models on just one GPU. In terms of training speed, the following figure shows the latency of training 100M samples with different batch sizes. Prefetch1 (shown in dark green) is the latency without pre-fetching, and Prefetch8 (shown in blue) is the latency with prefetching (prefetch mini-batch=8). This shows that prefetch flow optimization plays an important role in overall performance improvement. Each bar colored with darker colors in the figure is part of the Cache overhead, being controlled within 15% of the total training time after pre-fetching.
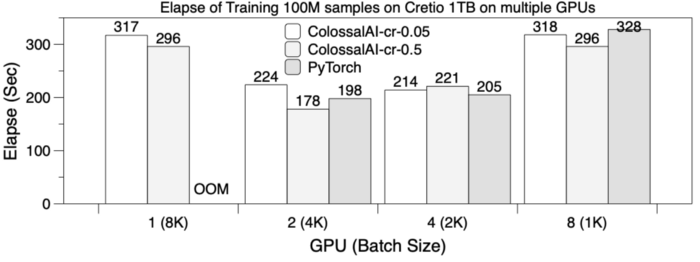
Scalability for Multiple GPUs
In our experiment, DLRM is trained with 100M samples on 8 GPUs, using table-wise sharding as EmbeddingBags in a parallel manner (global batch size = 8192, prefetch size = 4). The following figure shows the training latency for cases with a different number of GPUs. ColossalAI-cr-0.05 in the figures indicates the cache ratio is 0.05, while Colossal-cr-0.5 is 0.5. The PyTorch and Colossal-AI training times are mostly similar, but PyTorch encounters OOM issues when training on 1 GPU. It can be observed that adding GPUs (increasing to 4 or 8) does not bring significant performance benefits as synchronizing results requires huge communication overhead and table-wise sharding, leading to an unbalanced slice load. In other words, using multiple GPUs to scale embedding table training does not have significant advantages.
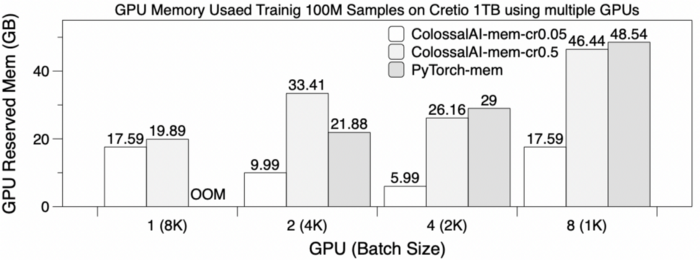
The graph below shows the maximum memory usage, varying across different numbers of GPUs. When using one GPU, only a software Cache method from Colossal-AI works, with the memory assumption of multiple cards in parallel showing a significant reduction.
The synthetic dlrm_datasets from Meta Research mimic the training access behavior of embedding tables. As a result, it is usually used as a reference for testing hardware and software designs that relate to recommendation systems. Subsequently, 500 million rows of these embedding table items are selected as sub-datasets, and two EmbeddingBags of 256GB and 128GB are constructed for testing.
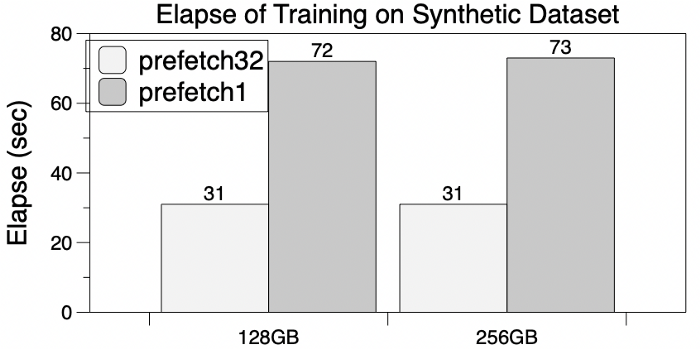
With GPU memory limitations, PyTorch has poor performance when training on one NVIDIA A100 GPU. In contrast, Colossal-AI’s software cache significantly eases GPU memory requirements, is capable of training embedding tables as large as 256GB, and also shows the potential to scale to terabytes. The acceleration is also demonstrated by running prefetching, where total training time decreases by 60% (#prefetches = 32) and GPU memory demand does not increase.
More About Colossal-AI

Colossal-AI is a user-friendly deep learning system that allows companies to maximize AI deployment efficiency while drastically reducing costs.
Since becoming open source to the public, Colossal-AI has reached №1 in trending projects on GitHub and Papers With Code multiple times, amidst other projects that have as many as 10K stars. Colossal-AI values open source community construction, providing English and Chinese tutorials, while supporting the latest cutting-edge applications such as PaLM and AlphaFold. Ultimately, Colossal-AI is constantly increasing the availability of AI solutions across a variety of fields, including medicine, autonomous vehicles, cloud computing, retail, chip production, etc.
Link
Project address: https://github.com/hpcaitech/ColossalAI
Reference
https://ai.facebook.com/blog/dlrm-an-advanced-open-source-deep-learning-recommendation-model/
Comments