
Methods that train and fine-tune AIGC (AI-Generated Content) models in a faster and cheaper manner have become extremely sought after for the commercialization and application of AIGC. Using previous experience regarding large model acceleration, Colossal-AI was able to release a complete open-source Stable Diffusion pretraining and fine-tuning solution. This solution reduces the pretraining cost by 6.5 times, and the hardware cost of fine-tuning by 7 times, while simultaneously speeding up the processes! The fine-tuning task flow can also be conveniently completed on an RTX 2070/3050 PC, allowing AIGC models such as Stable Diffusion to be available to those without access to extremely complicated machines.
GitHub Repo:https://github.com/hpcaitech/ColossalAI
Hot AIGC Track and High Cost
AIGC has recently risen to be one of the hottest topics in AI. With the emergence of cross-model applications that allow textually-generated images (Stable Diffusion, Midjourney, NovelAI, DALL-E, etc.), AIGC has attracted the attention of computer scientists and the public.

AIGC Generated Using Stable Diffusion[1]
AIGC is in high industry demand and has been labeled as one of the most prospective paths for the future of AI. The AI industry is expected to experience a technological revolution driven by the application of AIGC in text, audio, images/videos, games, the metaverse, and many other technological scenarios. The successful commercialization of AIGC in those fields represents the potential of a trillion-dollar market and has made related startups extremely appealing to investors. Startups like Stability AI and Jasper have already received hundreds of millions of dollars in funding, and have earned a spot in the ‘unicorn club’ after only being established for 1–2 years.
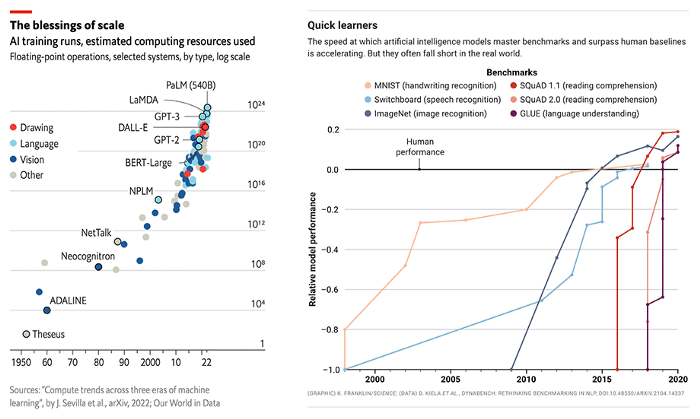
Correlation Between Increasing Model size and Performance[5, 6]
Unfortunately, large hardware requirements and training costs are still a severe impediment to the rapid growth of the AIGC industry. AIGC applications are usually built using large models such as GPT-3 or Stable Diffusion, which have been fine-tuned for specific downstream tasks. Take Stable Diffusion for example. Although the company behind it, Stability AI, was founded recently, the company maintains over 4,000 NVIDIA A100 GPU clusters and has spent over $50 million in operating costs. The Stable Diffusion v1 version of the model requires 150,000 A100 GPU Hours for a single training session.
Diffusion model
The idea of the diffusion model was first proposed in 2015 in a paper titled “Deep Unsupervised Learning using Nonequilibrium Thermodynamics”. In 2020, a paper titled “Denoising Diffusion Probabilistic Models (DDPM)” built upon this idea. Using the diffusion model, DALL-E 2, Imagen, and Stable Diffusion were able to achieve improved performance in generative tasks compared with traditional methods like generative adversarial networks (GAN), variable differentiation, autoencoder (VAE), autoregressive model (AR), etc.
The diffusion model consists of two processes: the forward diffusion process and the backward process. The forward diffusion process gradually adds Gaussian noise to an image until it becomes random noise, while the backward process is a de-noising process. The backward process uses multiple U-Nets to denoise until an image is generated.
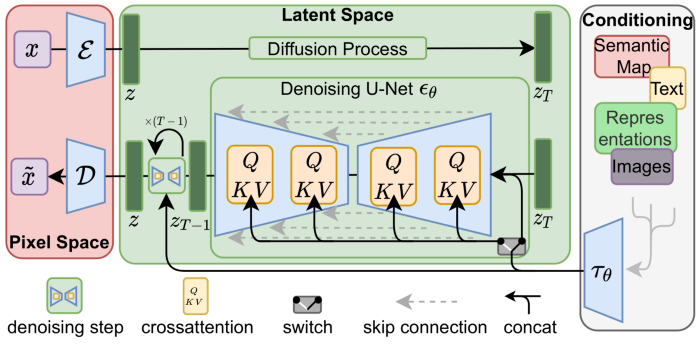
Latent Diffusion model
Compared to the traditional end-to-end training of deep learning models, the training process of the diffusion model is much more complicated. Taking stable diffusion as an example, the model contains a Frozen CLIP Textcoder and an Autoencoder in addition to the diffusion module. The frozen CLIP Textcoder is used to process text prompts and the Autoencoder is used to compress high-resolution images in latent space. The diffusion model also computes loss at every time step. This creates challenges in terms of memory and raises computing costs during training.
Lower Cost
Pretraining Speedup
For pretraining, the training speed typically increases with increasing batch size. This is also true for the diffusion model. Colossal-AI optimizes memory consumption with its ZeRO and Gemini modules. Replacing the Cross-Attention module with Flash-Attention also helps reduce GPU memory. As a result, users can train diffusion models on consumer-level GPUs such as RTX 3080. In this way, the batch size can also be increased to 256 on computing-specific GPUs such as an A100. This speeds up training by 6.5 times, in comparison to DDP training in stable-diffusion-v1-1. This allows diffusion model training, which can cost millions of dollars, to become much more affordable, opening opportunities for more people to explore AIGC applications!
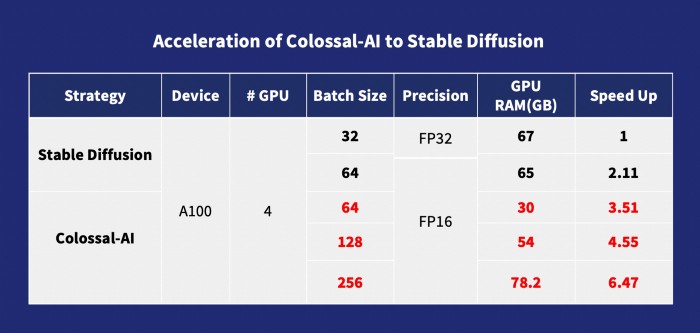
Acceleration of Colossal-AI to Stable Diffusion
Friendly Fine-tuning
Stable Diffusion’s pre-training uses a LAION-5B dataset with 585 billion image text pairs, which requires 240 TB of storage. Combined with the complexity of the model, it is inevitable that the cost of pre-training is extremely high. The Stability team spent over $50 million for a supercomputer of 4,000 A100 GPUs. A much more practical option for producing AIGC is using open-source pre-trained model weights that fine-tune downstream personalization tasks.
However, parallel training methods in existing open-source fine-tune solutions mainly use DDP (Distributed Data Parallelism), which requires huge amounts of memory consumption during training. Fine-tuning also needs an RTX 3090 or 4090 top-end consumer graphics card to start. At the same time, many open-source training frameworks do not give a complete training configuration and script at this stage, requiring users to spend extra time on tedious tasks and debugging.
Different from other solutions, Colossal-AI is the first solution to publicly release training configurations and training scripts simultaneously, allowing users to train the latest version of diffusion models for new downstream tasks at any time. This solution is more flexible and has a wider range of applications. Due to processes like GPU memory usage optimization, with Colossal-AI, the fine-tuning task process can be easily completed on a single consumer-level graphics card (such as GeForce RTX 2070/3050 8GB) on personal computers. Compared to RTX 3090 or 4090, the hardware cost can be reduced by about 7 times, greatly reducing the threshold and cost of AIGC models like Stable Diffusion. Users are therefore no longer limited to inferences with existing weights, and find it more convenient to complete personalized customization services. For tasks not sensitive to speed, Colossal-AI NVMe can be used, which uses low-cost disk space to reduce memory consumption.
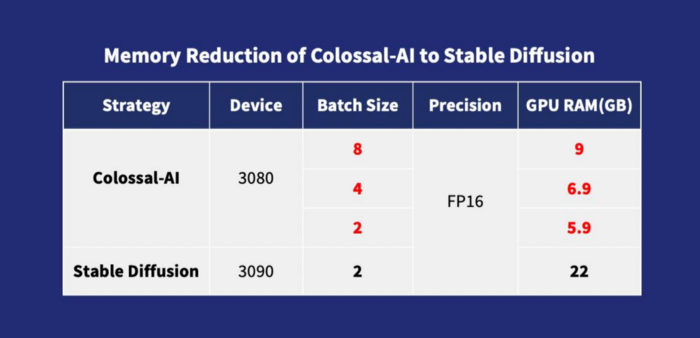
Memory Reduction of Colossal-AI to Stable Diffusion
Optimization
ZeRO + Gemini
Colossal-AI uses Zero Redundancy Optimizer (ZeRO) to eliminate memory redundancy, which greatly improves memory usage efficiency compared to classic data parallelism without sacrificing computational granularity and communication efficiency. Colossal-AI also incorporates Chunk-based memory management, which further improves the performance of ZeRO. A consecutive set of parameters in operational order is stored in a Chunk (a continuous memory space), and each Chunk is the same size. Chunk-based memory management ensures efficient use of network bandwidth between PCI-e and GPU-GPU, reduces the number of communications, and avoids potential memory fragmentation.
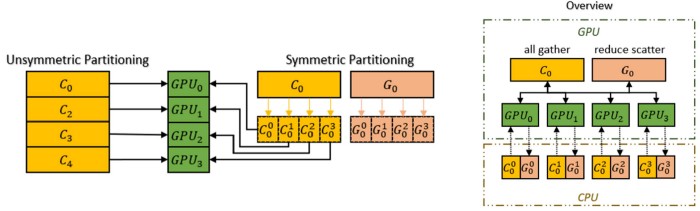
Chunk Strategy
Additionally, Colossal-AI’s heterogeneous memory manager, Gemini, can offload optimizer states from GPU to CPU which reduces GPU memory footprint. GPU memory and CPU memory (consisting of CPU DRAM or NVMe SSD memory) can be utilized simultaneously to break the memory wall of a single GPU, and further expand the scale of available models.
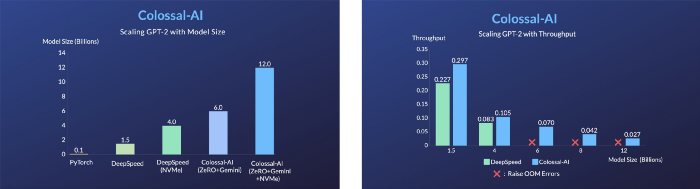
Increased Model Capacity of the Same Hardware with ZeRO + Gemini
Flash Attention
LDM (Latent Diffusion Models) implement multi-modal training by introducing cross-attention layers so that the diffusion model is more flexible, and supports class-condition, text-to-image, and layout-to-image. The cross-attention layer enhances computational overhead compared to the original CNN layer of the diffusion model, greatly increasing the training cost.
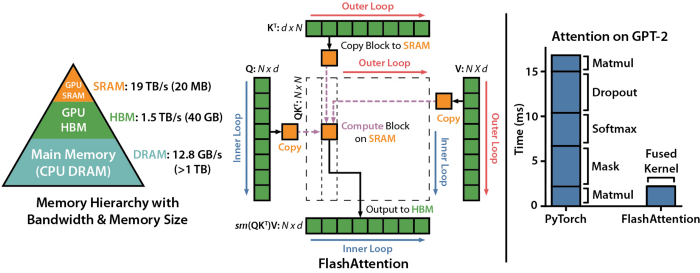
Overview of Flash Attention
By integrating flash attention, Colossal-AI improves the speed of attention modules by 104% and reduces peak end-to-end training memory by 23%. Flash attention is an efficient implementation of attention for long sequence tasks, and uses flatten to reduce the number of memory reads/writes between GPU high bandwidth memory (HBM). Flash attention also uses an approximate attention algorithm to block sparse attention, making it faster than existing approximate attention methods.
Other Optimizations
Colossal-AI integrates common optimization techniques such as FP16 and activation checkpoint. Activation checkpoints work by trading computation for memory. This method avoids storing intermediate activations of the computation graph for reverse computation, and instead recomputes them in the reverse pass, reducing memory usage. Another optimization technique used by Colossal-AI, FP16, essentially does not affect accuracy, and converts the original 32-bit floating operation to just 16-bits, reducing the use of GPU memory and improving efficiency.
An Easy Start
In contrast to common ML open-source projects, the most popular open-source diffusion project is built using PyTorch Lightning. PyTorch Lightning is a library designed to provide a concise, convenient, flexible, and efficient high-level interface for PyTorch. With the high-level abstraction offered by PyTorch Lightning, DL experiments have become more readable and reproducible for AI researchers. This versatile library has received over 20,500 stars so far.
Invited by PyTorch Lightning, Colossal-AI has been integrated as an official solution for large model training. From this integration, AI researchers can now train and utilize diffusion models more efficiently. One example is training stable diffusion models which can now kick-start with just a few lines of code.
from colossalai.nn.optimizer import HybridAdam
from lightning.pytorch import trainer
class MyDiffuser(LightningModule):
...
def configure_sharded_model(self) -> None:
# create your model here
self.model = construct_diffuser_model(...)
...
def configure_optimizers(self):
# use the specified optimizer
optimizer = HybridAdam(self.model.parameters(), self.lr)
...
model = MyDiffuser()
trainer = Trainer(accelerator="gpu", devices=1, precision=16, strategy="colossalai")
trainer.fit(model)
Colossal-AI and PyTorch Lightning also provide wonderful support and optimization for popular open-source models like OPT and from the open-source community, HuggingFace.
Lower Cost Model Fine-tuning
Colossal-AI fine-tunes the stable diffusion model from HuggingFace so users can train models with their own dataset efficiently. Users only need to modify the Dataloader to load their own fine-tuning dataset and read the pre-training weights. They can simply modify the yaml configuration file and run the training script to fine-tune their personalized model on their personal computer.
model:
target: ldm.models.diffusion.ddpm.LatentDiffusion
params:
your_sub_module_config:
target: your.model.import.path
params:
from_pretrained: 'your_file_path/unet/diffusion_pytorch_model.bin'
...
lightning:
trainer:
strategy:
target: pytorch_lightning.strategies.ColossalAIStrategy
params:
...
python main.py --logdir /your_log_dir -t -b config/train_colossalai.yaml
Inference
Colossal-AI also supports the native Stable Diffusion inference pipeline, which allows users to directly call the diffuser library and load their own saved model parameters after training or fine-tuning to perform inference directly without any other changes in code. This makes it easy for new users to get familiar with the inference process and allows users who are used to using the original framework to get started quickly.
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"your_ColoDiffusion_checkpoint_path"
).to("cuda")
image = pipe('your prompt', num_inference_steps=50)["sample"][0]
image.save('file path')

Images Generated With the Inference Pipeline Mentioned Above
Conclusion
We proposed a better pretraining and fine-tuning solution for AIGC, eg. Stable Diffusion, reducing the pretraining price by 6.5 times, as well as decreasing the hardware cost of personalized fine-tuning by 7 times. Anyone can now attempt to personalize AIGC fine-tuning tasks from a normal PC at home rather than on an expensive GPU server.
If you are interested, please check out our project on GitHub at: https://github.com/hpcaitech/ColossalAI
References
[1] https://github.com/CompVis/stable-diffusion
[2] https://openai.com/blog/triton/
[3] Dao, Tri, et al. “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.” arXiv preprint arXiv:2205.14135 (2022).
[4] Rombach, Robin, et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[5] Sevilla, Jaime, et al. “Compute trends across three eras of machine learning.” arXiv preprint arXiv:2202.05924 (2022).
[6] Kiela, Douwe, et al. “Dynabench: Rethinking benchmarking in NLP.” arXiv preprint arXiv:2104.14337 (2021).
[7] Fang, Jiarui, et al. "Parallel Training of Pre-Trained Models via Chunk-Based Dynamic Memory Management." IEEE Transactions on Parallel and Distributed Systems 34.1 (2022): 304-315.
[8] ZeRO: Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He. (2019) ZeRO: memory optimizations toward training trillion parameter models. arXiv:1910.02054 and In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC '20).
Comments