
Forbes News, the world’s leading voice, recently declared large AI models as one of six AI trends to watch for in 2022. As large-scale AI models continue their superior performances across different domains, trends emerge, leading to distinguished and efficient AI applications that have never been seen in the industry.
For example, Microsoft-owned GitHub and OpenAI partnered to launch Copilot recently. Copilot plays the role of an AI pair programmer, offering suggestions for code and entire functions in real-time. Such developments continue to make coding easier than before.
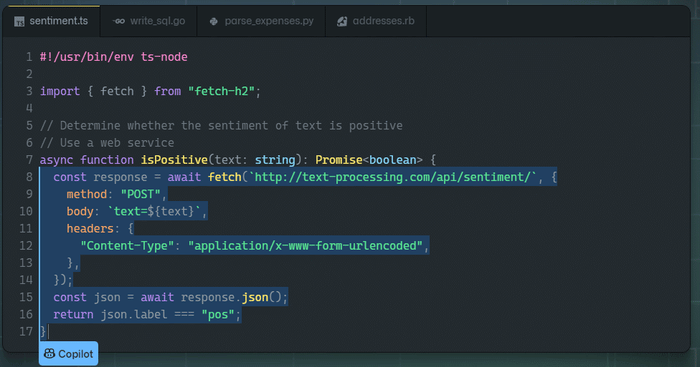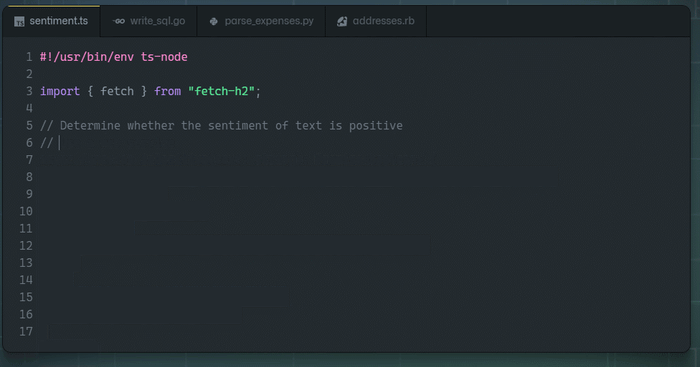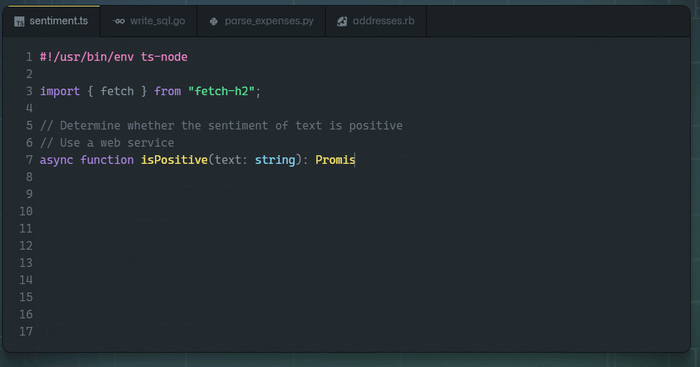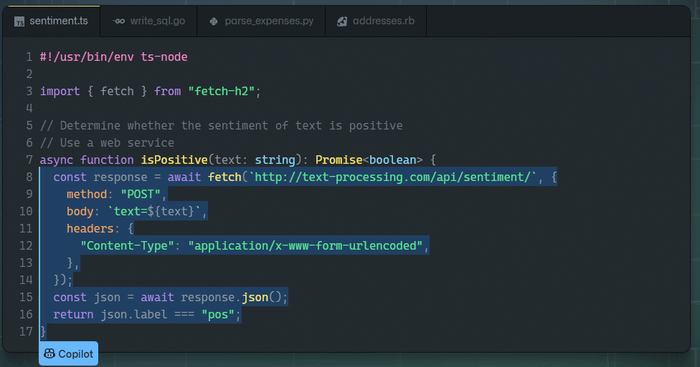
Another example released by OpenAI, DALL-E 2, is a powerful tool which creates original and realistic images as well as art from only simple text. One month later, Google announced its own robust text-to-image diffusion model called Imagen. Imagen delivers exceptional results, and accelerates the race of large AI models to a climax.

In recent years, the outstanding performance of model scaling has led to an escalation in the size of pre-trained models. Unfortunately, training and even simply fine-tuning large AI models are usually unaffordable, requiring tens or hundreds of GPUs. Existing deep learning frameworks like PyTorch and Tensorflow may not offer a satisfactory solution for very large AI models. Furthermore, advanced knowledge of AI systems is typically required for sophisticated configurations and optimization of specific models. Therefore, many AI users, such as engineers from small and medium-sized enterprises, can’t help but feel overwhelmed by the emergence of large AI models.
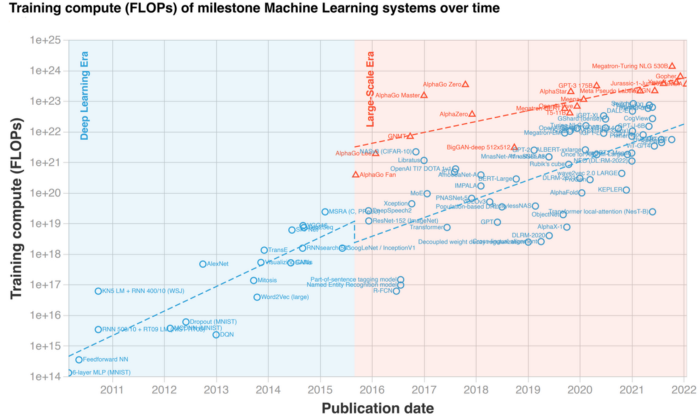
In fact, the core reasons for the increased cost of large AI models are GPU memory restrictions and the inability to accommodate sizeable models. In response to all of this, Colossal-AI developed the Gemini module, which efficiently manages and utilizes the heterogeneous memory of GPU and CPU and is expected to help solve the mentioned bottlenecks. Best of all, it is completely open-source and requires only minimal modifications to allow existing deep learning projects to be trained with much larger models on a single consumer-grade graphics card. In particular, it makes downstream tasks and application deployments such as large AI model fine-tuning and inference much easier. It even grants the convenience of training AI models at home!
Hugging Face is a popular AI community that strives to advance and democratize AI through open source and open science. Hugging Face has had success collating large-scale models into their own model hub with over 50,000 models, including trendy large AI models like GPT and OPT.

The open-source and large-scale AI system, Colossal-AI, now allows Hugging Face users to seamlessly develop their ML models in a distributed and easy manner. In the following paragraphs, we will take one of the most popular AI models in Hugging Face Hub, OPT from Meta, to demonstrate how to train and fine-tune your large AI models at a low cost with minimal modifications to your code.
Open source code: https://github.com/hpcaitech/ColossalAI
Accelerate Large Model OPT with Low Cost
About Open Pretrained Transformer (OPT)
Meta recently released Open Pretrained Transformer (OPT), a 175-Billion parameter AI language model. To encourage AI democratization in the community, Meta has released both the code and trained model weights, which stimulates AI programmers to perform various downstream tasks and application deployments. We will now demonstrate fine-tuning Casual Language Modelling with pre-training weights of the OPT model provided by Hugging Face Hub.
Configure with Colossal-AI
It is very simple to use the powerful features of Colossal-AI. Users only need a simple configuration file and are not required to alter their training logic to equip models with their desired features (e.g. mixed-precision training, gradient accumulation, multi-dimensional parallel training, and memory redundancy elimination).
Suppose we intend to develop the OPT on one GPU. We can accomplish this by leveraging heterogeneous training from Colossal-AI, which only requires users to add relevant items to the configuration files. Among the items added, tensor_placement_policy, which can be configured as cuda, cpu, or auto, determines our heterogeneous training strategy. Each training strategy has its distinct advantages:
cuda: puts all model parameters on GPU, suitable for scenarios where training persists without weights offloading;cpu: puts all model parameters on CPU, suitable for giant model training, only keeps weights on GPU memory that participate in current computation steps;auto: determines the number of parameters to keep on GPU by closely monitoring the current memory status. It optimizes the usage of GPU memory and minimizes the expensive data transmission between GPU and CPU.
For typical users, they can just select the auto strategy, which maximizes training efficiency by dynamically adapting its heterogeneous strategy with respect to its current memory state.
from colossalai.zero.shard_utils import TensorShardStrategy
zero = dict(model_config=dict(shard_strategy=TensorShardStrategy(),
tensor_placement_policy="auto"),
optimizer_config=dict(gpu_margin_mem_ratio=0.8))
Launch with Colossal-AI
With the configuration file ready, only a few lines of code are needed for the newly declared functions.
Firstly, awaken Colossal-AI through a single line of code in the configuration file. Colossal-AI will automatically initialize the distributed environment, read in configuration settings, and integrate the configuration settings into its components (i.e. models and optimizers).
colossalai.launch_from_torch(config='./configs/colossalai_zero.py')
After that, users may define their own datasets, models, optimizers, and loss functions per usual, or by using raw PyTorch code. Only their models need to be initialized under ZeroInitContext. In the given example, we adopt the OPTForCausalLM model along with its pretrained weights by Hugging Face, and make adjustments on the Wikitext dataset.
with ZeroInitContext(target_device=torch.cuda.current_device(),
shard_strategy=shard_strategy,
shard_param=True):
model = OPTForCausalLM.from_pretrained(
'facebook/opt-1.3b'
config=config
)
Next, use colossalai.initialize to integrate heterogeneous memory functions defined in the configuration file, into the training engine to enable the feature.
engine, train_dataloader, eval_dataloader, lr_scheduler = colossalai.initialize(
model=model,
optimizer=optimizer,
criterion=criterion,
train_dataloader=train_dataloader,
test_dataloader=eval_dataloader,
lr_scheduler=lr_scheduler
)
Remarkable Performance from Colossal-AI
On a single GPU, Colossal-AI’s automatic strategy provides remarkable performance gains from the ZeRO Offloading strategy by Microsoft DeepSpeed. Users can experience up to a 40% speedup, at a variety of model scales. However, when using a traditional deep learning training framework like PyTorch, a single GPU can no longer support the training of models at such a scale.
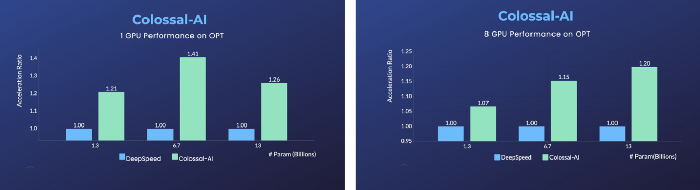
Adopting the distributed training strategy with 8 GPUs is as simple as adding a -nprocs 8 to the training command of Colossal-AI!
Behind the Scenes
Such remarkable improvements come from Colossal-AI’s efficient heterogeneous memory management system, Gemini. To put it simply, Gemini uses a few warmup steps during model training to collect memory usage information from PyTorch computational graphs. After warm-up, and before performing each operation, Gemini pre-allocates memory for the operator equivalent to its peak usage based on the collected memory usage records. At the same time, it re-allocates some model tensors from GPU memory to CPU memory.
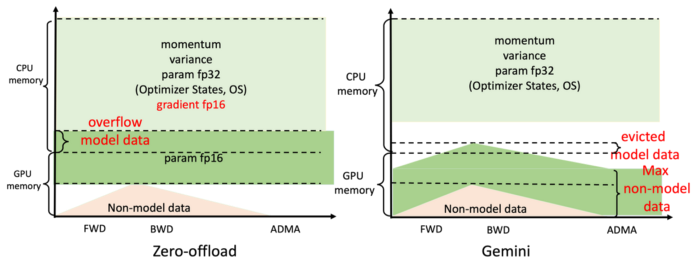
The inbuilt memory manager by Gemini attaches a state to each tensor, including HOLD, COMPUTE, FREE, etc. Based on the queried memory usage, the manager constantly converts the tensor states, and adjusts tensor positions. Compared to the static memory classification by DeepSpeed’s ZeRO Offload, Colossal-AI Gemini employs a more efficient use of GPU and CPU memory, maximizes model capacities, and balances training speeds, all with small amounts of hardware equipment.
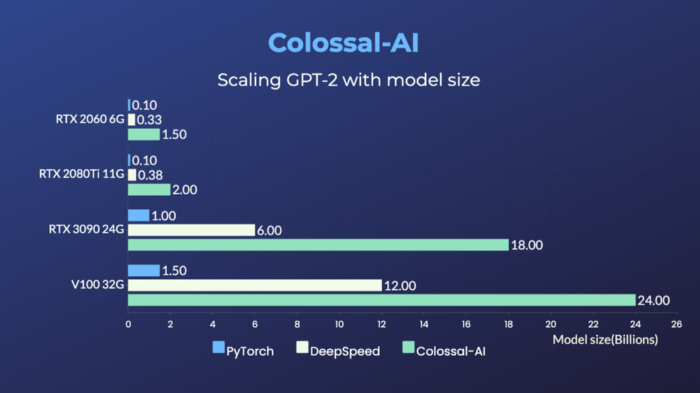
For the representative of large models, GPT, Colossal-AI is capable of training up to 1.5 billion parameters on a gaming laptop with RTX 2060 6GB. For a PC with RTX3090 24GB, Colossal-AI can train GPT with 18 billion parameters. Colossal-AI can also bring significant improvements to high performance graphics cards such as a Tesla V100.
Furthermore: convenient and efficient parallelizations
Parallel and distributed technologies are vital methods to further accelerate model training. To train the world’s largest and most advanced AI models within the shortest time, efficient distributed parallelization is still a necessity. Issues found in existing solutions include limited parallel dimension, low efficiency, poor versatility, difficult deployment, and lack of maintenance. With this in mind, Colossal-AI uses technologies such as efficient multi-dimensional parallelism and heterogeneous parallelism to allow users to deploy large AI models efficiently and rapidly with minimal modifications to their code.
To counter complications arising from data, pipeline, and 2.5D parallelism simultaneously, a simple line of code declaration suffices with Colossal-AI. The typical system/framework method of hacking into underlined code logic is no longer necessary.
parallel = dict(
pipeline=2,
tensor=dict(mode='2.5d', depth = 1, size=4)
)
For a super-large AI model such as GPT-3, Colossal-AI only needs half the computing resources compared to the NVIDIA solution to start training. If the same computing resources were used, the speed could be further increased by 11%, which could reduce the training cost of GPT-3 by over a million dollars.
In theory, this sounds fantastic, but what about in practice? Colossal-AI has proven its capabilities in application to real-world issues across a variety of industries, including autonomous driving, cloud computing, retail, medicine, and chip production.

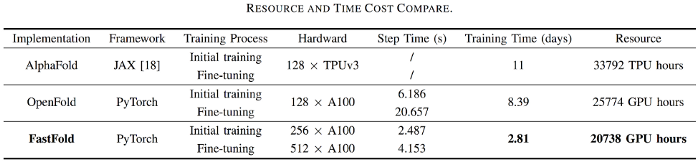
For, AlphaFold, which is used for protein structure prediction, our team has introduced FastFold, based on the Colossal-AI acceleration scheme. FastFold has successfully surpassed other schemes including those proposed by Google and Columbia University. It successfully reduces the training time of AlphaFold from 11 days to 67 hours, simultaneously lowering the overall cost. Moreover, the process of long sequence inference is accelerated by about 9.3 to 11.6 times.
Colossal-AI values open source community construction. We offer detailed tutorials, and support the latest cutting-edge applications such as PaLM and AlphaFold. Colossal-AI will regularly produce new and innovative features. We always welcome suggestions and discussions, and would be more than willing to help if you encounter any issues. You can raise an issue here or create a discussion topic in our forum. Your suggestions are highly appreciated. Recently, Colossal-AI reached №1 in trending projects on Github and Papers With Code, together with projects that have as many as 10K stars.
Link
Project address: https://github.com/hpcaitech/ColossalAI
Reference
[1] Sevilla, J., Heim, L., Ho, A., Besiroglu, T., Hobbhahn, M., & Villalobos, P. (2022). Compute trends across three eras of machine learning. arXiv preprint arXiv:2202.05924.
[2] Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E., … & Norouzi, M. (2022). Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. arXiv preprint arXiv:2205.11487.
[3] https://github.com/features/copilot
[4] https://github.com/huggingface/transformers
[6] https://www.infoq.com/news/2022/06/meta-opt-175b/
[7] ZeRO: Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He. (2019) ZeRO: memory optimizations toward training trillion parameter models. arXiv:1910.02054 and In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC '20).
[8] ZeRO-Offload: Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, Yuxiong He. (2021) ZeRO-Offload: Democratizing Billion-Scale Model Training. arXiv:2101.06840 and USENIX ATC 2021.
[9] ZeRO-Infinity: Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, Yuxiong He. (2021) ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning. arXiv:2104.07857 and SC 2021.
Comments